In this series of post, we shall learn the algorithm for image segmentation and implementation of the same using Tensorflow.
Why is deconvolutional layer so important?
Image segmentation is just one of the many use cases of this layer. In any type of computer vision application where resolution of final output is required to be larger than input, this layer is the de-facto standard. This layer is used in very popular applications like Generative Adversarial Networks(GAN), image super-resolution, surface depth estimation from image, optical flow estimation etc. These are some direct applications of deconvolution layer. It has now also been deployed in other applications like fine-grained recogntion, object detection. In these use cases, the existing systems can use deconvolution layer to merge responses from different convolutional layers and can significantly boosts up their accuracy.
1. What is image segmentation?
2. What is deconvolutional layer?
3. Initialization strategy for deconvolutional layer.
4. Writing a deconvolutional layer for Tensorflow.
Let’s get started.
1. What is Image Segmentation?

Image segmentation
image segmentation is the process of dividing an image into multiple segments(each segment is called super-pixel). And each super-pixel may represent one common entity just like a super-pixel for dog’s head in the figure. Segmentation creates a representation of the image which is easier to understand and analyze as shown in the example. Segmentation is a computationally very expensive process because we need to classify each pixel of the image.
Convolutional neural networks are the most effective way to understand images. But there is a problem with using convolutional neural networks for Image Segmentation.
But, How to use convolutional neural networks for image segmentation:
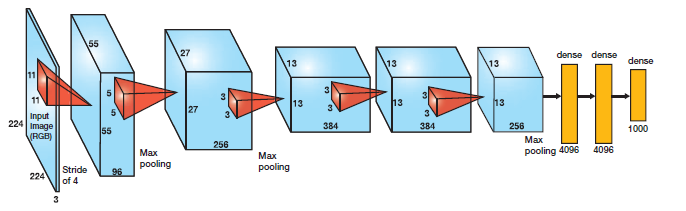
Look at the figure below: This shows alexnet and size at each layer. It’s fed an image of 224*224*3=150528 and after 7 layers, we get a vector of size 4096. This is the representation of the input image that’s great for image classification and detection problems.
However, For this, we use an upsampling convolutional layer which is called deconvolutional layer or fractionally strided convolutional layer.
2. What is Fractionally Strided convolution or deconvolution?
2.1 Detailed understanding of fractionally strided convolution/deconvolution:

Figure 1
Kernel size: 4 (figure 1)
Stride: 2
The convolution process is depicted in figure 2 wherein filter slides horizontally across x(top) to produce output y(left). As usual, to get the output, weights at each location are multiplied with corresponding input and summed up. And since the stride is 2, the output map is just half the resolution of input map.
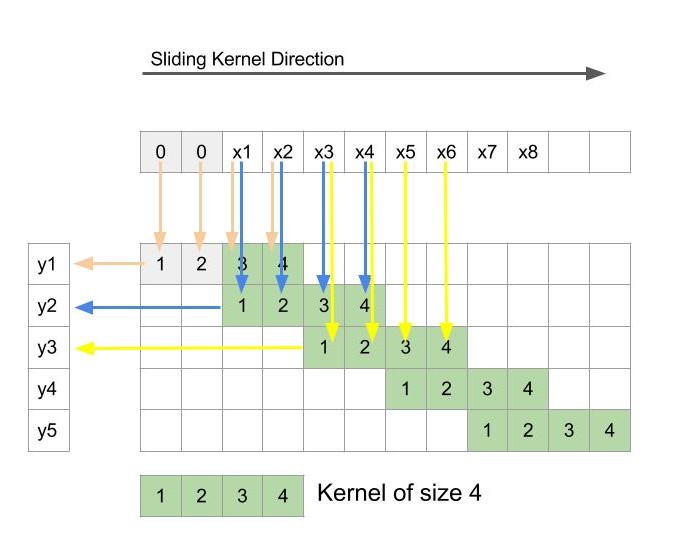
FIGURE 2: Depiction of usual convolution process with 1-D input
Now, let’s reverse these operations.
In order to flip the input and output, we will first reverse the direction of arrows from figure 2 to obtain the figure 3. Now the input is y and the output is x. Let’s see how the inputs and outputs are related.
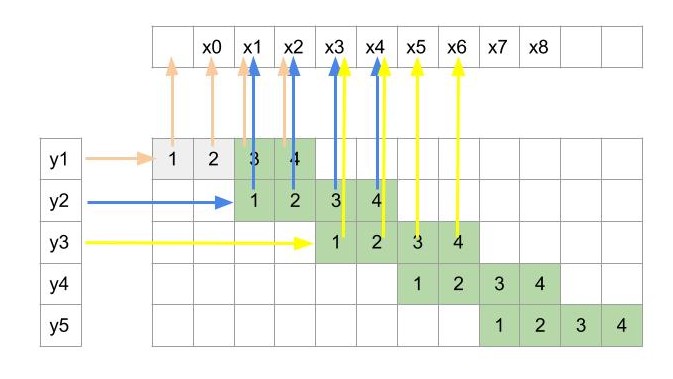
Figure 3: Reversing the data-flow in convolution
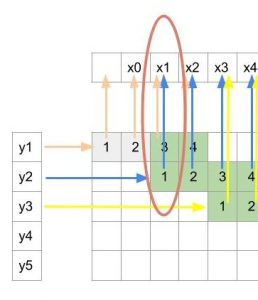
Figure 4
Since y2 was obtained from x1 to x4 during convolution, so here y2 will be an input for only those 4 x’s i.e. x1 to x4. Similarly, y3 will be input for x3 to x6. So, each y will have the contribution towards 4 consecutive x.
Also from the arrows, we can see that x1 depends only on y1 and y2(pointed in figure 4). Similarly, x2 also depends only on y1 and y2. So each output x here depends only on two consecutive inputs y whereas in the previous convolution operation the output was dependent on 4 inputs.
Figure 5 shows what all inputs(y) are used to compute an output(x).
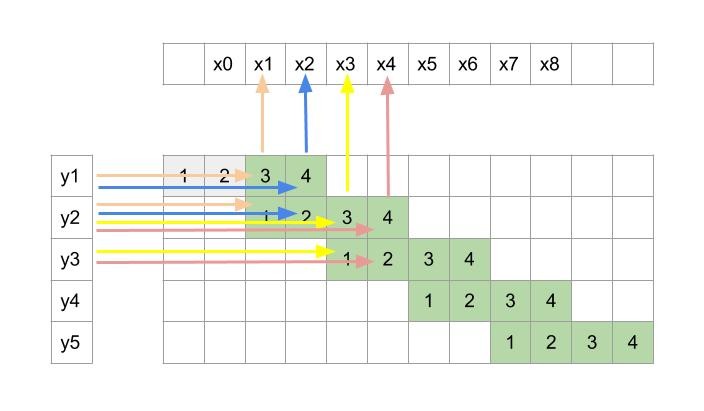
Figure 5: Shows what all inputs(y) are used to compute an output(x)
This obviously is very different from normal convolution. Now the big question is, can this operation be cast as a convolution operation wherein a kernel is slid across y(vertically in our case as y is arranged vertically) to get output x.
From the figure 5 we can see x1 is calculated using only kernel indices 3 and 1. But x2 is calculated using indices 4 and 2. This can be thought as two different kernels are active for different outputs which is different from the regular convolution where a single kernel is used throughout for all the outputs. Here one kernel is responsible for outputs at x1, x3, x5 …x2k-1 and other kernel produces x2, x4 …. x2k. The problem with carrying out the operation in this way is that it’s very inefficient. The reason is that we will first have to use one kernel for producing outputs at odd numbered pixels and then use other kernel for even numbered pixels. Finally we will have to stitch these different sets of outputs by arranging them alternately to get final output.
We will now see a trick which can make this process efficient.
Lets put one void value(zero) between every two consecutive y. We obtain figure 6. Here we have not changed any connectivity between x and y. Each x depends on the same set of y’s and two newly inserted zeros. Since zeros do not change the summation, we still have the same operation. But the beauty of this little tweak is that each x now uses the same single kernel. We do not need to have two different sets of kernels. A single kernel with size 4 can be slide across y to get the same output x. Since x is twice the resolution of y, we now have a methodology to increase the resolution.
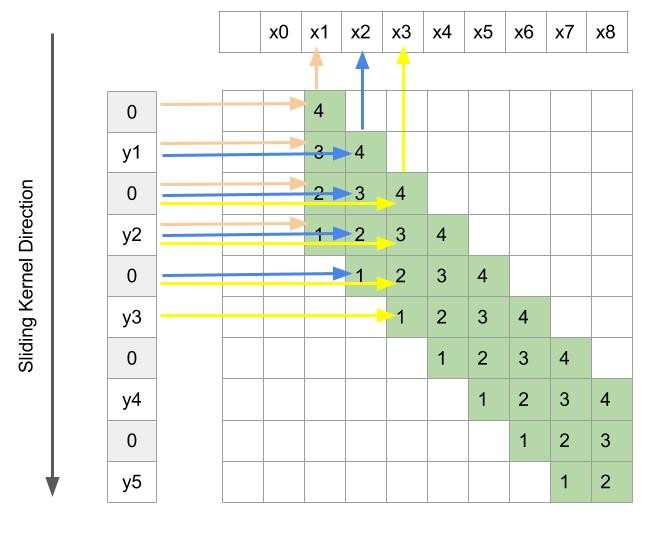
Figure 6: Depiction of fractionally strided convolution
So a deconvolution operation can be performed in the same way as a normal convolution. We just have to insert zeros between the consecutive inputs and define a kernel of an appropriate size and just slide it with stride 1 to the get the output. This will ensure an output with a resolution higher than the resolution of its inputs.
An added benefit with this operation is that since weights are associated with operation and that too in a linear way(multiplying and adding), we can easily back-propagate through this layer.
So, hopefully this gives you detailed understanding and intuition for a fractionally strided convolutional layer. In the next step, we shall cover the initialization of this layer.
We discussed earlier that the concept of a deconvolution operation stems from the concept of upsampling of features which resembles bilinear interpolation. So it makes sense that the idea for initialization of the layers is heavily inspired and designed such that it can perform a bilinear interpolation.
3.1 Image Upsampling:

FIGURE 7
3.2 How to use this for deconvolutional layer initialization?

FIGURE 8

FIGURE 9

FIGURE 10
In tensorflow, it can be carried out as below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
def get_bilinear_filter(filter_shape, upscale_factor): ##filter_shape is [width, height, num_in_channels, num_out_channels] kernel_size = filter_shape[1] ### Centre location of the filter for which value is calculated if kernel_size % 2 == 1: centre_location = upscale_factor - 1 else: centre_location = upscale_factor - 0.5 bilinear = np.zeros([filter_shape[0], filter_shape[1]]) for x in range(filter_shape[0]): for y in range(filter_shape[1]): ##Interpolation Calculation value = (1 - abs((x - centre_location)/ upscale_factor)) * (1 - abs((y - centre_location)/ upscale_factor)) bilinear[x, y] = value weights = np.zeros(filter_shape) for i in range(filter_shape[2]): weights[:, :, i, i] = bilinear init = tf.constant_initializer(value=weights, dtype=tf.float32) bilinear_weights = tf.get_variable(name="decon_bilinear_filter", initializer=init, shape=weights.shape) return bilinear_weights |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
def upsample_layer(bottom, n_channels, name, upscale_factor): kernel_size = 2*upscale_factor - upscale_factor%2 stride = upscale_factor strides = [1, stride, stride, 1] with tf.variable_scope(name): # Shape of the bottom tensor in_shape = tf.shape(bottom) h = ((in_shape[1] - 1) * stride) + 1 w = ((in_shape[2] - 1) * stride) + 1 new_shape = [in_shape[0], h, w, n_channels] output_shape = tf.stack(new_shape) filter_shape = [kernel_size, kernel_size, n_channels, n_channels] weights = get_bilinear_filter(filter_shape,upscale_factor) deconv = tf.nn.conv2d_transpose(bottom, weights, output_shape, strides=strides, padding='SAME') return deconv |
So, we have covered the most important part for implementing segmentation in Tensorflow. In the follow up post, we shall implement the complete algorithm for image segmentation and will see some results.


