
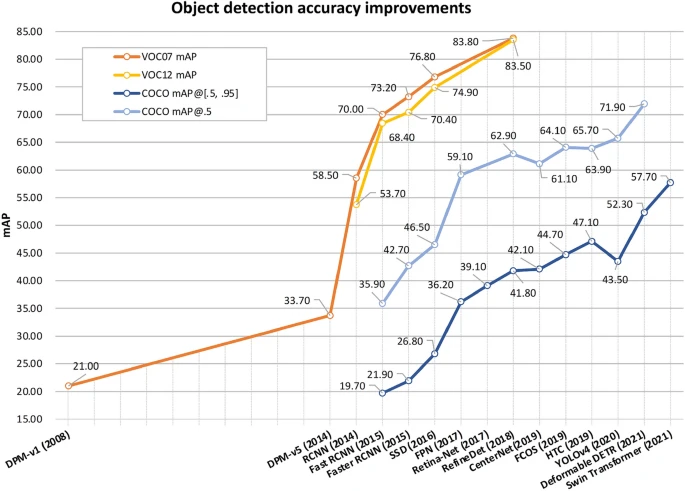
The world of computer vision changed forever 2011 onwards, when convolutional neural networks (CNNs) revolutionized object detection by providing a significant leap in accuracy and efficiency compared to earlier methods like the Viola-Jones framework, which primarily relied on handcrafted features and boosted classifiers.
CNN-based models like Faster R-CNN, YOLO, and CenterNet brought about groundbreaking changes: Faster R-CNN introduced the concept of region proposal networks to streamline object detection, YOLO provided real-time detection with impressive speed and accuracy, and CenterNet improved on keypoint-based object detection, making the entire process more robust and efficient. These advancements laid the foundation for the modern, highly capable object detection systems we see today.
Rise of Transformers
![]()
The attention mechanism was first introduced in the landmark paper “Attention Is All You Need” by Vaswani et al. in 2017, which revolutionized the architecture of neural networks by replacing the traditional recurrent structures with a self-attention mechanism. This approach allowed models to focus on different parts of the input sequence adaptively, leading to better understanding and parallelization of data. This innovation laid the foundation for the development of highly accurate models in various domains. Notably, the attention mechanism inspired the creation of Vision Transformers (ViT) and the Detection Transformer (DETR). DETR adapted the self-attention mechanism for object detection by treating object detection as a set prediction problem, enabling end-to-end detection with superior performance compared to traditional pipelines. ViT, on the other hand, utilized self-attention to process image patches akin to words in a sequence, transforming computer vision tasks and achieving state-of-the-art accuracy by leveraging the ability to model long-range dependencies effectively. Together, these advancements brought the transformative power of the attention mechanism from NLP into computer vision, giving rise to models with unprecedented accuracy and efficiency.
Key Differences Between ViTs and CNNs:
- Feature Extraction Approach: CNNs use convolutional layers to create feature maps by applying learned filters, capturing local spatial patterns. ViTs split images into patches and use self-attention to learn global relationships among these patches, resulting in a more holistic feature extraction.
- Inductive Bias: CNNs have a strong inductive bias towards local spatial correlations due to their use of fixed-size filters and weight sharing. ViTs, on the other hand, have minimal inductive bias, allowing them to learn relationships across the entire image but often requiring larger datasets to generalize well.
- Data Requirements: ViTs typically need more training data compared to CNNs to achieve comparable performance, as they do not inherently embed assumptions about local spatial structures. CNNs are more efficient on smaller datasets because their design incorporates specific biases that align well with natural image structures.
- Global vs. Local Context: ViTs naturally model long-range dependencies across an entire image using attention, which helps in understanding global patterns and relationships. CNNs build hierarchical features, which makes them efficient for capturing localized information but can struggle with modeling the entire image’s global context as effectively as ViTs.
Challenges and Innovations
While transformers offer promising advancements, they come with their own set of challenges. The computational cost of transformers is significantly higher than that of CNNs, particularly when dealing with high-resolution images. However, innovations like sparse attention, efficient transformers, and hybrid models that combine CNNs with transformers are helping to mitigate these issues. If you look at the current state of the art object detection models, transformers are already right there at the top.
Future Prospects
The future of object detection is moving towards models that combine the strengths of transformers with other architectural advancements to achieve optimal performance. Self-supervised learning and multimodal transformers, which combine vision and language understanding, are also gaining traction, making object detection systems smarter and more adaptable to diverse real-world applications.
Transformers have set a new benchmark for what’s possible in object detection, pushing the boundaries of accuracy and efficiency. As research progresses, we can expect even more sophisticated models that bring together the best of both transformers and traditional approaches, further advancing the capabilities of object detection systems.


