
In this Tensorflow tutorial, we shall build a convolutional neural network based image classifier using Tensorflow. If you are just getting started with Tensorflow, then it would be a good idea to read the basic Tensorflow tutorial here.
To demonstrate how to build a convolutional neural network based image classifier, we shall build a 6 layer neural network that will identify and separate images of dogs from that of cats. This network that we shall build is a very small network that you can run on a CPU as well. Traditional neural networks that are very good at doing image classification have many more paramters and take a lot of time if trained on CPU. However, in this post, my objective is to show you how to build a real-world convolutional neural network using Tensorflow rather than participating in ILSVRC. Before we start with Tensorflow tutorial, let’s cover basics of convolutional neural network. If you are already familiar with conv-nets(and call them conv-nets), you can move to part-2 i.e. Tensorflow tutorial.
Part-1: Basics of Convolutional Neural network (CNN):
Neural Networks are essentially mathematical models to solve an optimization problem. They are made of neurons, the basic computation unit of neural networks. A neuron takes an input(say x), do some computation on it(say: multiply it with a variable w and adds another variable b ) to produce a value (say; z= wx+b). This value is passed to a non-linear function called activation function(f) to produce the final output(activation) of a neuron. There are many kinds of activation functions. One of the popular activation function is Sigmoid, which is:
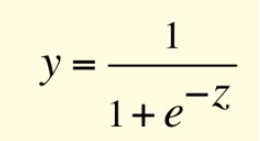
The neuron which uses sigmoid function as an activation function will be called Sigmoid neuron. Depending on the activation functions, neurons are named and there are many kinds of them like RELU, TanH etc(remember this). One neuron can be connected to multiple neurons, like this:
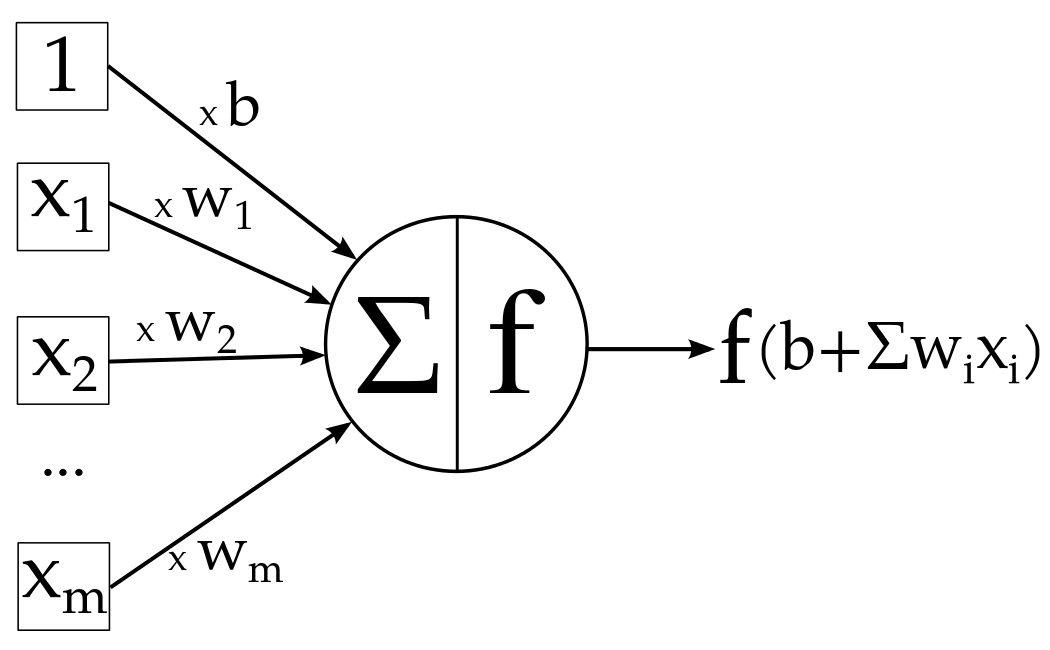
In this example, you can see that the weights are the property of the connection, i.e. each connection has a different weight value while bias is the property of the neuron. This is the complete picture of a sigmoid neuron which produces output y:
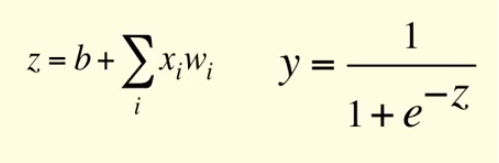
Layers:
If you stack neurons in a single line, it’s called a layer; which is the next building block of neural networks.
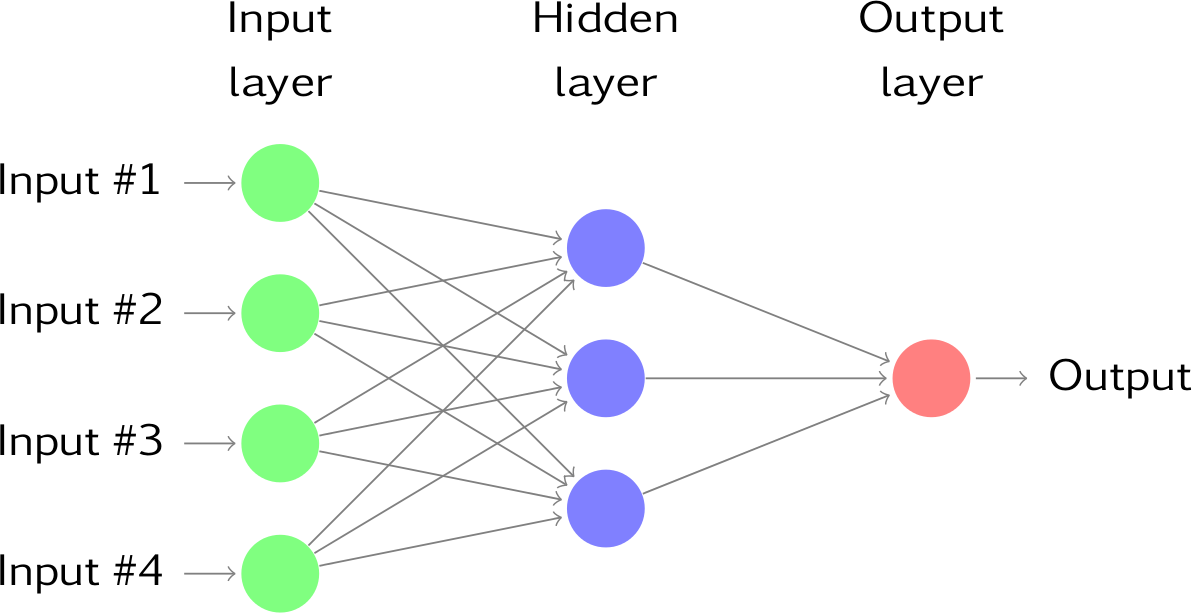
As you can see above, the neurons in green make 1 layer which is the first layer of the network through which input data is passed to the network. Similarly, the last layer is called output layer as shown in red. The layers in between input and output layer are called hidden layers. In this example, we have only 1 hidden layer shown in blue. The networks which have many hidden layers tend to be more accurate and are called deep network and hence machine learning algorithms which uses these deep networks are called deep learning.
Types of layers:
Typically, all the neurons in one layer, do similar kind of mathematical operations and that’s how that a layer gets its name(Except for input and output layers as they do little mathematical operations). Here are the most popular kinds of layers you should know about:
-
Convolutional Layer:
Convolution is a mathematical operation that’s used in single processing to filter signals, find patterns in signals etc. In a convolutional layer, all neurons apply convolution operation to the inputs, hence they are called convolutional neurons. The most important parameter in a convolutional neuron is the filter size, let’s say we have a layer with filter size 5*5*3. Also, assume that the input that’s fed to convolutional neuron is an input image of size of 32*32 with 3 channels.
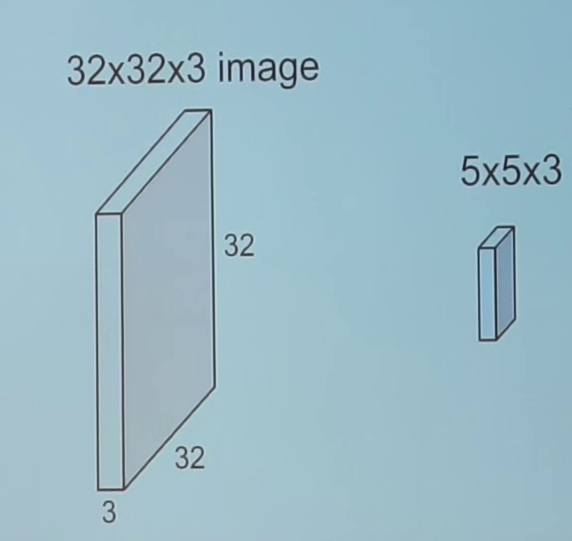 Let’s pick one 5*5*3(3 for number of channels in a colored image) sized chunk from image and calculate convolution(dot product) with our filter(w). This one convolution operation will result in a single number as output. We shall also add the bias(b) to this output.
Let’s pick one 5*5*3(3 for number of channels in a colored image) sized chunk from image and calculate convolution(dot product) with our filter(w). This one convolution operation will result in a single number as output. We shall also add the bias(b) to this output.
 Let’s pick one 5*5*3(3 for number of channels in a colored image) sized chunk from image and calculate convolution(dot product) with our filter(w). This one convolution operation will result in a single number as output. We shall also add the bias(b) to this output.
Let’s pick one 5*5*3(3 for number of channels in a colored image) sized chunk from image and calculate convolution(dot product) with our filter(w). This one convolution operation will result in a single number as output. We shall also add the bias(b) to this output.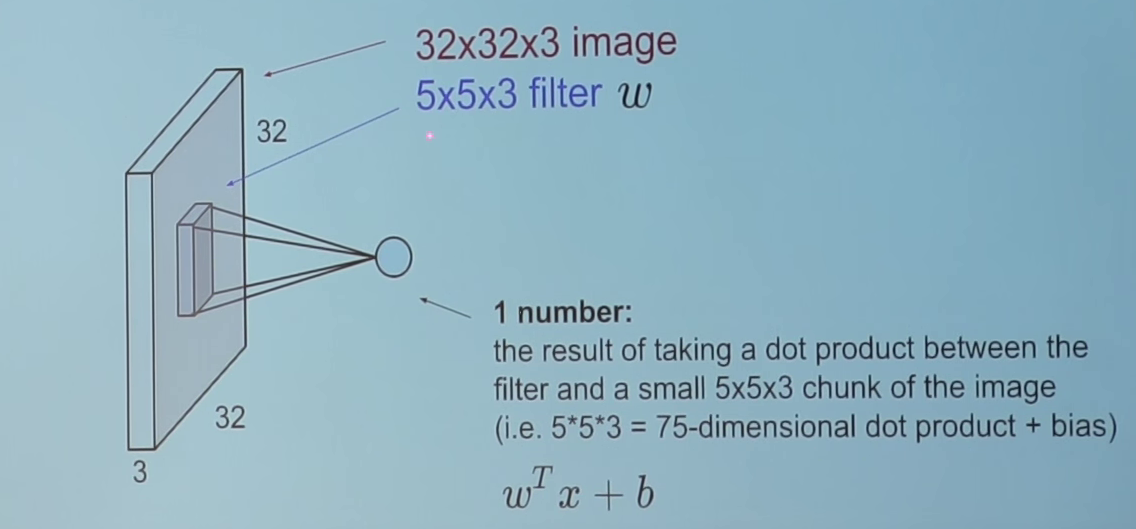
In order to calculate the dot product, it’s mandatory for the 3rd dimension of the filter to be same as the number of channels in the input. i.e. when we calculate the dot product it’s a matrix multiplication of 5*5*3 sized chunk with 5*5*3 sized filter.
We shall slide convolutional filter over whole input image to calculate this output across the image as shown by a schematic below: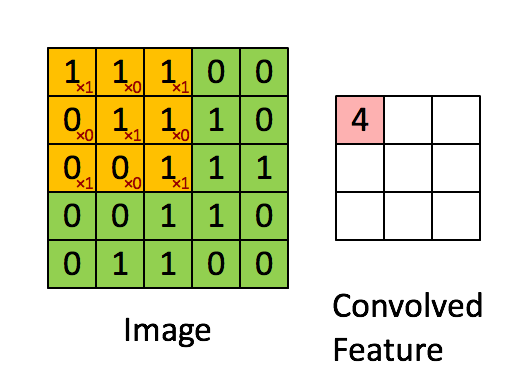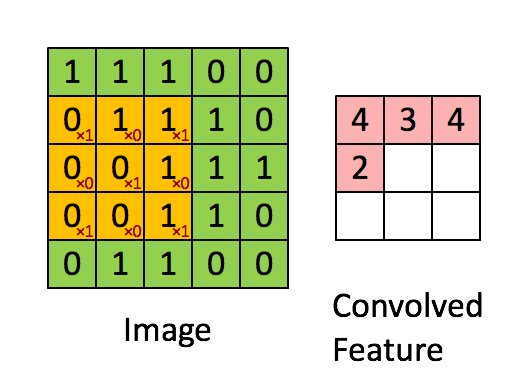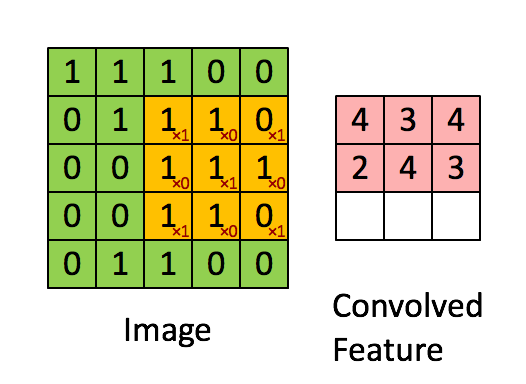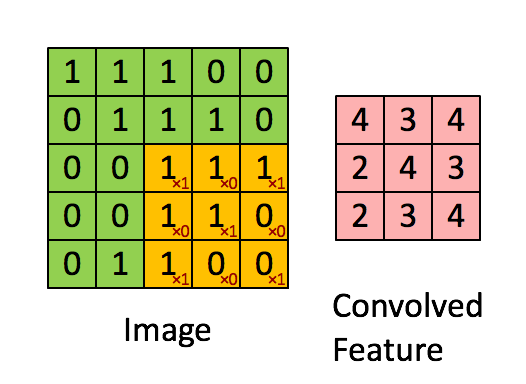
In this case, we slide our window by 1 pixel at a time. If some cases, people slide the windows by more than 1 pixel. This number is called stride.
If you concatenate all these outputs in 2D, we shall have an output activation map of size 28*28(can you think of why 28*28 from 32*32 with the filter of 5*5 and stride of 1). Typically, we use more than 1 filter in one convolution layer. If we have 6 filters in our example, we shall have an output of size 28*28*6.
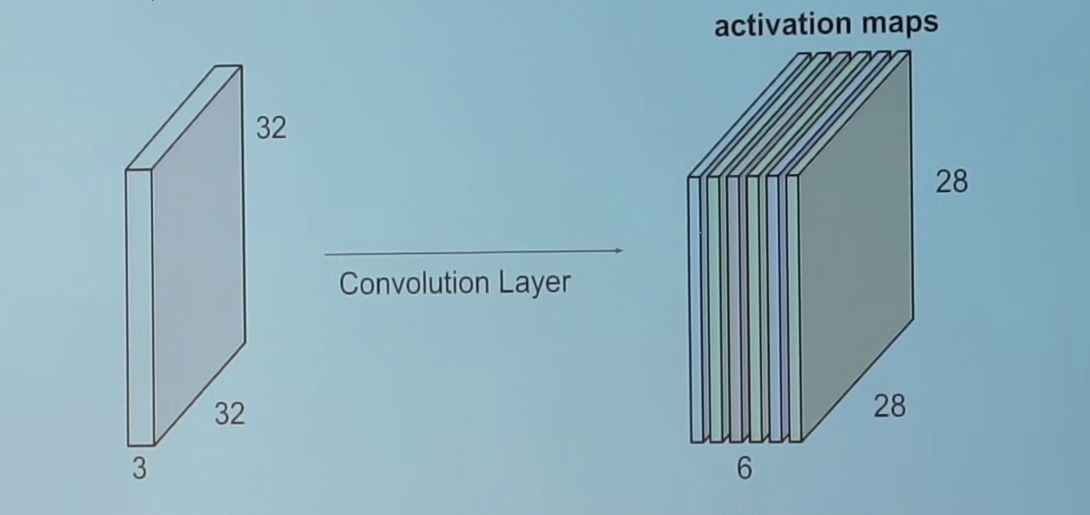
As you can see, after each convolution, the output reduces in size(as in this case we are going from 32*32 to 28*28). In a deep neural network with many layers, the output will become very small this way, which doesn’t work very well. So, it’s a standard practice to add zeros on the boundary of the input layer such that the output is the same size as input layer. So, in this example, if we add a padding of size 2 on both sides of the input layer, the size of the output layer will be 32*32*6 which works great from the implementation purpose as well. Let’s say you have an input of size N*N, filter size is F, you are using S as stride and input is added with 0 pad of size P. Then, the output size will be:
(N-F+2P)/S +1
2. Pooling Layer:
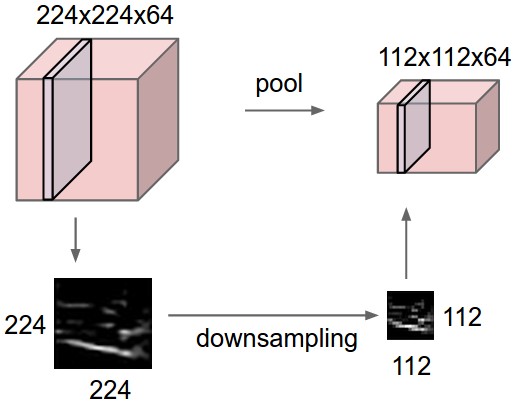
Pooling layer is mostly used immediately after the convolutional layer to reduce the spatial size(only width and height, not depth). This reduces the number of parameters, hence computation is reduced. Also, less number of parameters avoid overfitting(don’t worry about it now, will describe it little later). The most common form of pooling is Max pooling where we take a filter of size F*F and apply the maximum operation over the F*F sized part of the image.
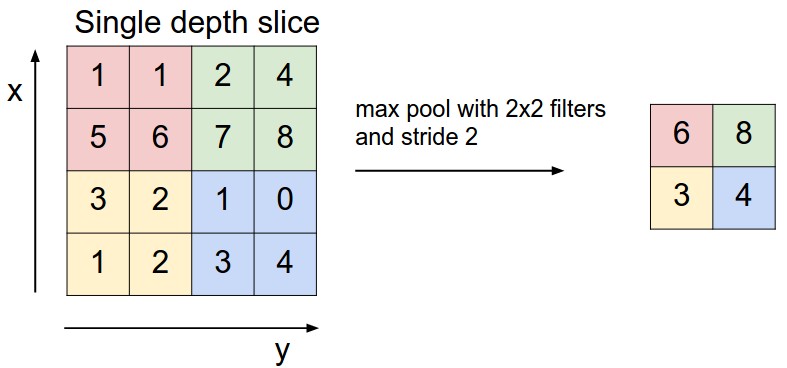
If you take the average in place of taking maximum, it will be called average pooling, but it’s not very popular.
If your input is of size w1*h1*d1 and the size of the filter is f*f with stride S. Then the output sizes w2*h2*d2 will be:
w2= (w1-f)/S +1
h2=(h1-f)/S +1
d2=d1
Most common pooling is done with the filter of size 2*2 with a stride of 2. As you can calculate using the above formula, it essentially reduces the size of input by half.
3. Fully Connected Layer:
If each neuron in a layer receives input from all the neurons in the previous layer, then this layer is called fully connected layer. The output of this layer is computed by matrix multiplication followed by bias offset.
Understanding Training process:
Deep neural networks are nothing but mathematical models of intelligence which to a certain extent mimic human brains. When we are trying to train a neural network, there are two fundamental things we need to do:
-
The Architecture of the network:
When designing the architecture of a neural network you have to decide on: How do you arrange layers? which layers to use? how many neurons to use in each layer etc.? Designing the architecture is slightly complicated and advanced topic and takes a lot of research. There are many standard architectures which work great for many standard problems. Examples being AlexNet, GoogleNet, InceptionResnet, VGG etc. In the beginning, you should only use the standard network architectures. You could start designing networks after you get a lot of experience with neural nets. Hence, let’s not worry about it now.
-
Correct weights/parameters:
Once you have decided the architecture of the network; the second biggest variable is the weights(w) and biases(b) or the parameters of the network. The objective of the training is to get the best possible values of the all these parameters which solve the problem reliably. For example, when we are trying to build the classifier between dog and cat, we are looking to find parameters such that output layer gives out probability of dog as 1(or at least higher than cat) for all images of dogs and probability of cat as 1((or at least higher than dog) for all images of cats.
You can find the best set of parameters using a process called Backward propagation, i.e. you start with a random set of parameters and keep changing these weights such that for every training image we get the correct output. There are many optimizer methods to change the weights that are mathematically quick in finding the correct weights. GradientDescent is one such method(Backward propagation and optimizer methods to change the gradient is a very complicated topic. But we don’t need to worry about it now as Tensorflow takes care of it).
So, let’s say, we start with some initial values of parameters and feed 1 training image(in reality multiple images are fed together) of dog and we calculate the output of the network as 0.1 for it being a dog and 0.9 of it being a cat. Now, we do backward propagation to slowly change the parameters such that the probability of this image being a dog increases in the next iteration. There is a variable that is used to govern how fast do we change the parameters of the network during training, it’s called learning rate. If you think about it, we want to maximise the total correct classifications by the network i.e. we care for the whole training set; we want to make these changes such that the number of correct classifications by the network increases. So we define a single number called cost which indicates if the training is going in the right direction. Typically cost is defined in such a way that; as the cost is reduced, the accuracy of the network increases. So, we keep an eye on the cost and we keep doing many iterations of forward and backward propagations(10s of thousands sometimes) till cost stops decreasing. There are many ways to define cost. One of the simple one is mean root square cost. Let’s say \(y_{prediction}\) is the vector containing the output of the network for all the training images and \(y_{actual}\) is the vector containing actual values(also called ground truth) of these labeled images. So, if we minimize the distance between these two variables, it would be a good indicator of the training. So, we define the cost as the average of these distances for all the images:
$$ cost=0.5 \sum_{i=0}^n (y_{actual}-y_{prediction})^2 $$
This is a very simple example of cost, but in actual training, we use much more complicated cost measures, like cross-entropy cost. But Tensorflow implements many of these costs so we don’t need to worry about the details of these costs at this point in time.
After training is done, these parameters and architecture will be saved in a binary file(called model). In production set-up when we get a new image of dog/cat to classify, we load this model in the same network architecture and calculate the probability of the new image being a cat/dog. This is called inference or prediction.
For computational simplicity, not all training data is fed to the network at once. Rather, let’s say we have total 1600 images, we divide them in small batches say of size 16 or 32 called batch-size. Hence, it will take 100 or 50 rounds(iterations) for complete data to be used for training. This is called one epoch, i.e. in one epoch the networks sees all the training images once. There are a few more things that are done to improve accuracy but let’s not worry about everything at once.
Part-2: Tensorflow tutorial-> Building a small Neural network based image classifier:
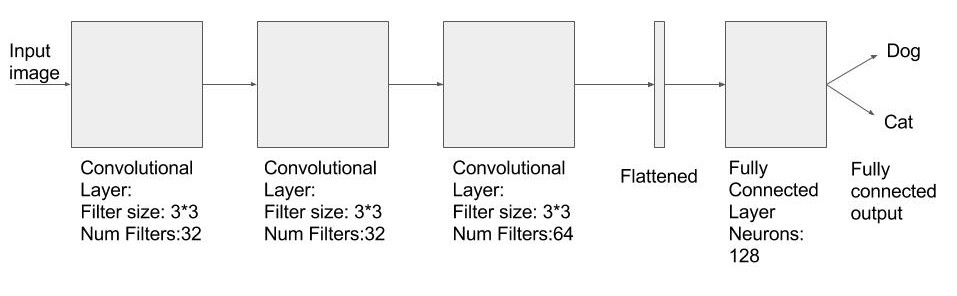
Network that we will implement in this tutorial is smaller and simpler (than the ones that are used to solve real-world problems) so that you can train this on your cpu as well. While training, images from both the classes(dogs/cats) are fed to a convolutional layer which is followed by 2 more convolutional layers. After convolutional layers, we flatten the output and add two fully connected layer in the end. The second fully connected layer has only two outputs which represent the probability of an image being a cat or a dog.
a) Pre-requisites:
i) OpenCV: We use openCV to read images of cats/Dogs so you will have to install it.
ii) Shape function:
if you have multi-dimensional Tensor in TF, you can get the shape of it by doing this:
|
1 2 3 4 5 |
a = tf.truncated_normal([16,128,128,3]) sess = tf.Session() sess.run(tf.initialize_all_variables()) sess.run(tf.shape(a)) |
output will be: array([ 16, 128, 128, 3], dtype=int32)
You can reshape this to a new 2D Tensor of shape[16 128*128*3]= [16 49152].
|
1 2 3 |
b=tf.reshape(a,[16,49152]) sess.run(tf.shape(b)) |
Output: array([16, 49152], dtype=int32)
iii) Softmax: is a function that converts K-dimensional vector ‘x’ containing real values to the same shaped vector of real values in the range of (0,1), whose sum is 1. We shall apply the softmax function to the output of our convolutional neural network in order to, convert the output to the probability for each class.
$$ o(x)_{j}= \frac{e^{x_{i}}}{ \sum_{n=1}^N e^{x_{n}}} \,\, for \, j=1….N $$
b) Reading inputs:
I have used 2000 images of dogs and cats each from Kaggle dataset but you could use any n image folders on your computer which contain different kinds of objects. Typically, we divide our input data into 3 parts:
- Training data: we shall use 80% i.e. 0 images for training.
- Validation data: 20% images will be used for validation. These images are taken out of training data to calculate accuracy independently during the training process.
- Test set: separate independent data for testing which has around 400 images. Sometimes due to something called Overfitting; after training, neural networks start working very well on the training data(and very similar images) i.e. the cost becomes very small, but they fail to work well for other images. For example, if you are training a classifier between dogs and cats and you get training data from someone who takes all images with white backgrounds. It’s possible that your network works very well on this validation data-set, but if you try to run it on an image with a cluttered background, it will most likely fail. So, that’s why we try to get our test-set from an independent source.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
classes = ['dogs', 'cats'] num_classes = len(classes) train_path='training_data' # validation split validation_size = 0.2 # batch size batch_size = 16 data = dataset.read_train_sets(train_path, img_size, classes, validation_size=validation_size) |
dataset is a class that I have created to read the input data. This is a simple python code that reads images from the provided training and testing data folders.
The objective of our training is to learn the correct values of weights/biases for all the neurons in the network that work to do classification between dog and cat. The Initial value of these weights can be taken anything but it works better if you take normal distributions(with mean zero and small variance). There are other methods to initialize the network but normal distribution is more prevalent. Let’s create functions to create initial weights quickly just by specifying the shape(Remember we talked about truncated_normal function in the earlier post).
|
1 2 3 4 5 6 |
def create_weights(shape): return tf.Variable(tf.truncated_normal(shape, stddev=0.05)) def create_biases(size): return tf.Variable(tf.constant(0.05, shape=[size])) |
c) Creating network layers:
i) Building convolution layer in TensorFlow:
tf.nn.conv2d function can be used to build a convolutional layer which takes these inputs:
input= the output(activation) from the previous layer. This should be a 4-D tensor. Typically, in the first convolutional layer, you pass n images of size width*height*num_channels, then this has the size [n width height num_channels]
filter= trainable variables defining the filter. We start with a random normal distribution and learn these weights. It’s a 4D tensor whose specific shape is predefined as part of network design. If your filter is of size filter_size and input fed has num_input_channels and you have num_filters filters in your current layer, then filter will have following shape:
[filter_size filter_size num_input_channels num_filters]
strides= defines how much you move your filter when doing convolution. In this function, it needs to be a Tensor of size>=4 i.e. [batch_stride x_stride y_stride depth_stride]. batch_stride is always 1 as you don’t want to skip images in your batch. x_stride and y_stride are same mostly and the choice is part of network design and we shall use them as 1 in our example. depth_stride is always set as 1 as you don’t skip along the depth.
padding=SAME means we shall 0 pad the input such a way that output x,y dimensions are same as that of input.
After convolution, we add the biases of that neuron, which are also learnable/trainable. Again we start with random normal distribution and learn these values during training.
Now, we apply max-pooling using tf.nn.max_pool function that has a very similar signature as that of conv2d function.
|
1 2 3 4 5 |
tf.nn.max_pool(value=layer, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') |
Notice that we are using k_size/filter_size as 2*2 and stride of 2 in both x and y direction. If you use the formula (w2= (w1-f)/S +1; h2=(h1-f)/S +1 ) mentioned earlier we can see that output is exactly half of input. These are most commonly used values for max pooling.
Finally, we use a RELU as our activation function which simply takes the output of max_pool and applies RELU using tf.nn.relu
All these operations are done in a single convolution layer. Let’s create a function to define a complete convolutional layer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
def create_convolutional_layer(input, num_input_channels, conv_filter_size, num_filters): ## We shall define the weights that will be trained using create_weights function. weights = create_weights(shape=[conv_filter_size, conv_filter_size, num_input_channels, num_filters]) ## We create biases using the create_biases function. These are also trained. biases = create_biases(num_filters) ## Creating the convolutional layer layer = tf.nn.conv2d(input=input, filter=weights, strides=[1, 1, 1, 1], padding='SAME') layer += biases ## We shall be using max-pooling. layer = tf.nn.max_pool(value=layer, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') ## Output of pooling is fed to Relu which is the activation function for us. layer = tf.nn.relu(layer) return layer |
ii) Flattening layer:
The Output of a convolutional layer is a multi-dimensional Tensor. We want to convert this into a one-dimensional tensor. This is done in the Flattening layer. We simply use the reshape operation to create a single dimensional tensor as defined below:
|
1 2 3 4 5 6 7 |
def create_flatten_layer(layer): layer_shape = layer.get_shape() num_features = layer_shape[1:4].num_elements() layer = tf.reshape(layer, [-1, num_features]) return layer |
iii) Fully connected layer:
Now, let’s define a function to create a fully connected layer. Just like any other layer, we declare weights and biases as random normal distributions. In fully connected layer, we take all the inputs, do the standard z=wx+b operation on it. Also sometimes you would want to add a non-linearity(RELU) to it. So, let’s add a condition that allows the caller to add RELU to the layer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
def create_fc_layer(input, num_inputs, num_outputs, use_relu=True): #Let's define trainable weights and biases. weights = create_weights(shape=[num_inputs, num_outputs]) biases = create_biases(num_outputs) layer = tf.matmul(input, weights) + biases if use_relu: layer = tf.nn.relu(layer) return layer |
So, we have finished defining the building blocks of the network.
iv) Placeholders and input:
Now, let’s create a placeholder that will hold the input training images. All the input images are read in dataset.py file and resized to 128 x 128 x 3 size. Input placeholder x is created in the shape of [None, 128, 128, 3]. The first dimension being None means you can pass any number of images to it. For this program, we shall pass images in the batch of 16 i.e. shape will be [16 128 128 3]. Similarly, we create a placeholder y_true for storing the predictions. For each image, we have two outputs i.e. probabilities for each class. Hence y_pred is of the shape [None 2] (for batch size 16 it will be [16 2].
|
1 2 3 4 5 |
x = tf.placeholder(tf.float32, shape=[None, img_size,img_size,num_channels], name='x') y_true = tf.placeholder(tf.float32, shape=[None, num_classes], name='y_true') y_true_cls = tf.argmax(y_true, dimension=1) |
v) network design:
We use the functions defined above to create various layers of the network.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
layer_conv1 = create_convolutional_layer(input=x, num_input_channels=num_channels, conv_filter_size=filter_size_conv1, num_filters=num_filters_conv1) layer_conv2 = create_convolutional_layer(input=layer_conv1, num_input_channels=num_filters_conv1, conv_filter_size=filter_size_conv2, num_filters=num_filters_conv2) layer_conv3= create_convolutional_layer(input=layer_conv2, num_input_channels=num_filters_conv2, conv_filter_size=filter_size_conv3, num_filters=num_filters_conv3) layer_flat = create_flatten_layer(layer_conv3) layer_fc1 = create_fc_layer(input=layer_flat, num_inputs=layer_flat.get_shape()[1:4].num_elements(), num_outputs=fc_layer_size, use_relu=True) layer_fc2 = create_fc_layer(input=layer_fc1, num_inputs=fc_layer_size, num_outputs=num_classes, use_relu=False) |
vi) Predictions:
As mentioned above, you can get the probability of each class by applying softmax to the output of fully connected layer.
y_pred = tf.nn.softmax(layer_fc2,name="y_pred")
y_pred contains the predicted probability of each class for each input image. The class having higher probability is the prediction of the network. y_pred_cls = tf.argmax(y_pred, dimension=1)
Now, let’s define the cost that will be minimized to reach the optimum value of weights. We will use a simple cost that will be calculated using a Tensorflow function softmax_cross_entropy_with_logits which takes the output of last fully connected layer and actual labels to calculate cross_entropy whose average will give us the cost.
|
1 2 3 4 |
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=layer_fc2, labels=y_true) cost = tf.reduce_mean(cross_entropy) |
VII) Optimization:
Tensorflow implements most of the optimisation functions. We shall use AdamOptimizer for gradient calculation and weight optimization. We shall specify that we are trying to minimise cost with a learning rate of 0.0001.
optimizer = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(cost)
As you know, if we run optimizer operation inside session.run(), in order to calculate the value of cost, the whole network will have to be run and we will pass the training images in a feed_dict(Does that make sense? Think about, what variable would you need to calculate cost and keep going up in the code). Training images are passed in a batch of 16(batch_size) in each iteration.
|
1 2 3 4 5 6 7 8 9 |
batch_size = 16 x_batch, y_true_batch, _, cls_batch = data.train.next_batch(batch_size) feed_dict_train = {x: x_batch, y_true: y_true_batch} session.run(optimizer, feed_dict=feed_dict_tr) |
where next_batch is a simple python function in dataset.py file that returns the next 16 images to be passed for training. Similarly, we pass the validation batch of images independently to in another session.run() call.
|
1 2 3 4 5 6 7 |
x_valid_batch, y_valid_batch, _, valid_cls_batch = data.valid.next_batch(train_batch_size) feed_dict_val = {x: x_valid_batch, y_true: y_valid_batch} val_loss = session.run(cost, feed_dict=feed_dict_val) |
Note that in this case, we are passing cost in the session.run() with a batch of validation images as opposed to training images. In order to calculate the cost, the whole network(3 convolution+1 flattening+2 fc layers) will have to be executed to produce layer_fc2(which is required to calculate cross_entropy, hence cost). However, as opposed to training, this time optimization optimizer = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(cost) will not be run(as we only have to calculate cost). This is what changes the gradients and weights and is very computationally expensive. We can calculate the accuracy on validataion set using true labels(y_true) and predicted labels(y_pred).
|
1 2 3 |
correct_prediction = tf.equal(y_pred_cls, y_true_cls) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) |
We can calculate the validation accuracy by passing accuracy in session.run() and providing validation images in a feed_dict.
val_acc = session.run(accuracy,feed_dict=feed_dict_validate)
Similarly, we also report the accuracy for the training images.
acc = session.run(accuracy, feed_dict=feed_dict_train)
As, training images along with labels are used for training, so in general training accuracy will be higher than validation. We report training accuracy to know that we are at least moving in the right direction and are at least improving accuracy in the training dataset. After each Epoch, we report the accuracy numbers and save the model using saver object in Tensorflow.
|
1 2 |
saver.save(session, 'dogs-cats-model') |
So, this is how the complete train function looks like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
def train(num_iteration): global total_iterations for i in range(total_iterations, total_iterations + num_iteration): x_batch, y_true_batch, _, cls_batch = data.train.next_batch(batch_size) x_valid_batch, y_valid_batch, _, valid_cls_batch = data.valid.next_batch(batch_size) feed_dict_tr = {x: x_batch, y_true: y_true_batch} feed_dict_val = {x: x_valid_batch, y_true: y_valid_batch} session.run(optimizer, feed_dict=feed_dict_tr) if i % int(data.train.num_examples/batch_size) == 0: val_loss = session.run(cost, feed_dict=feed_dict_val) epoch = int(i / int(data.train.num_examples/batch_size)) show_progress(epoch, feed_dict_tr, feed_dict_val, val_loss) saver.save(session, 'dogs-cats-model') total_iterations += num_iteration |
This code is slightly long as it’s a real world example. So, please go here, clone the code and run the train.py file to start the training. This is how the output will look like:
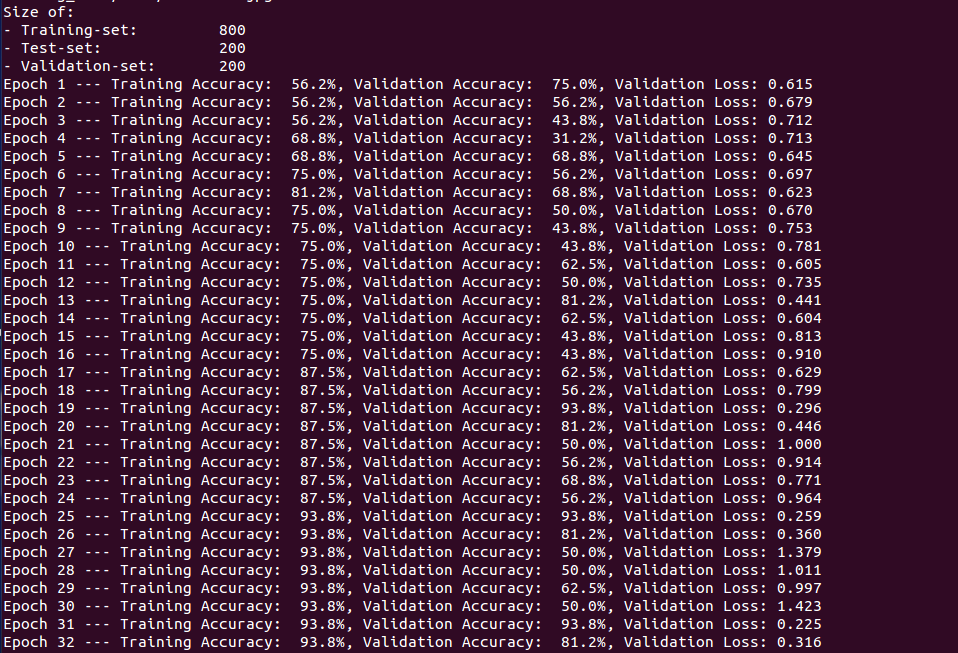
This is a small network and is not state-of-the-art to build an image classifier but it’s very good for learning specially when you are just getting started. For our training, we get more than 80% accuracy on validation set. As we save the model during training, we shall use this to run on our own images.
Prediction:
After you are done with training, you shall notice that there are many new files in the folder:
- dogs-cats-model.meta
- dogs-cats-model.data-00000-of-00001
- dogs-cats-model.index
- checkpoint
File dogs-cats-model.meta contains the complete network graph and we can use this to recreate the graph later. We shall use a saver object provided by Tensorflow to do this.
|
1 2 |
saver = tf.train.import_meta_graph('flowers-model.meta') |
The file dogs-cats-model.data-00000-of-00001 contains the trained weights(values of variables) of the network. So, once we have recreated the graph, we shall restore the weights.
|
1 2 |
saver.restore(sess, tf.train.latest_checkpoint('./')) |
In order to get the prediction of the network, we need to read & pre-process the input image in the same way(as training), get hold of y_pred on the graph and pass it the new image in a feed dict. So, let’s do that:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
image = cv2.imread(filename) # Resizing the image to our desired size and # preprocessing will be done exactly as done during training image = cv2.resize(image, (image_size, image_size), cv2.INTER_LINEAR) images.append(image) images = np.array(images, dtype=np.uint8) images = images.astype('float32') images = np.multiply(images, 1.0/255.0) #The input to the network is of shape [None image_size image_size num_channels]. Hence we reshape. x_batch = images.reshape(1, image_size,image_size,num_channels) graph = tf.get_default_graph() y_pred = graph.get_tensor_by_name("y_pred:0") ## Let's feed the images to the input placeholders x= graph.get_tensor_by_name("x:0") y_true = graph.get_tensor_by_name("y_true:0") y_test_images = np.zeros((1, 2)) feed_dict_testing = {x: x_batch, y_true: y_test_images} result=sess.run(y_pred, feed_dict=feed_dict_testing) |
Finally, we can run a new image of dog/cat using predict script.
|
1 2 3 |
python predict.py test_dog.jpg [[ 0.99398661 0.00601341]] |
Output contains the probabilities of the input image being a dog or a cat. In this example, probability of being dog is much higher than that of cat.
Congratulations! you have learnt how to build and train an image classifier using convolutional neural networks.
Trained Model and data: In the git repository, I have only added 500 images for each class. But it takes more than 500 images of dogs/cats to train even a decent classifier. So, I have trained this model on 2400 images of each class. You can download these images from here. This Mini-cat-dog-dataset is a subset of Kaggle Dog-Cat dataset and is not owned by us. You can also use my trained model available here to generate the prediction.
The complete code is available here. Please let me know your questions and feedback in the comments below. These comments and feedback are my motivation to create more tutorials 🙂 .
Practice exercises: 1. For the fun of it, you can use the same script to train another classifier on your own dataset(Take at least 500 images of each class). Depending on the kind of problem you choose, you would notice:
Depending on the problem, the sample network does better or worse. For example, if you train a classifier on bikes, airplanes and cars it will take lesser training data and you will get higher accuracy. But if you take a problem which is harder then you would need a lot of data and it may still not be enough.
2. A very standard practice in computer vision is to augment the data, i.e. you can slightly rotate, crop, zoom-in, flip the original image to generate new training examples. This in general leads to improved accuracy. For practice, you can augment and train again, try and report how many minimum images would you need to get the same level of accuracy or how much accuracy gain will be achieved by this.

