Neural network architecture design is one of the key hyperparameters in solving problems using deep learning and computer vision. Various neural networks are compared on two key factors i.e. accuracy and computational requirement. In general, as we aim to design more accurate neural networks, the computational requirement increases. In this post, we shall learn about the search for more accurate neural network architectures without worrying about computational need. We shall also see how neural networks can be taught to design themselves and how this technique is being used to discover better neural network architectures(AutoML or Neural Architecture Search).
Imagenet challenge: the standard benchmark
Identifying images has always been hard for computers. In order to quantify, how good computers can be in recognizing objects in images, Imagenet challenge was designed. Imagenet is an image data set that consists of 1.2 million images of 1000 categories on which the participants shall train their models and then test the models on a separate dataset of 50000 images. This way everyone trains on the same data set and tests on the same data set, hence we can have a fair comparison of just the algorithms(neural network architectures after the rise of deep learning). Every year, the brightest brains in the industry and academia build an algorithms/models that can do better at identifying these images.
Alexnet and search for better neural network architecture begins
The first big breakthrough for deep learning arrived in 2012 when Alexnet architecture achieved 57 % top-1 accuracy on Imagenet dataset. In the subsequent years, many better architectures were designed to take this top-1 accuracy to 83%. The key improvement to get a better accuracy on imagenet has been the better neural network architecture design. And since the training and test sets are large, we assume that if an architecture does better on Imagenet, then it would, in general, do very well on image recognition tasks(this seems to be truer in case of transfer learning). We are still looking for architectures that can achieve more on Imagenet challenge. How much better can we do? Can we reach the level after which we have only irreducible error left(i.e. the inherent error due to randomness and natural variability in a system)? The ultimate neural network architecture that achieves this seemingly God-like feat, I would call the ultimate Neural Network architecture. In this post, let’s explore the efforts in this direction and the progress so far.
Initial Networks: Just a deep stack of layers
Initial Neural networks like Alexnet and VGGNet were simply various layers stacked after one another. Look at Alexnet:
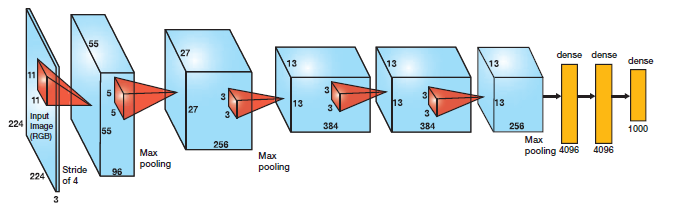
Architecture of Alexnet which won 2012 Imagenet challenge.
Can we simply get deeper?

As more experiments were done with network architecture, the first intuition was to increase the number of layers to get a higher accuracy. But as the number of layers was increased there were two problems that were encountered:
- Vanishing Gradients: During back-propagation, the gradient flow from the last layers of the network becomes almost negligible by the time it reaches the first few layers. This means that the earlier layers don’t learn at all. This is called the vanishing gradient problem. However, this problem is shown to be solved with normalized initialization and intermediate normalization layers(like batch-norm etc).
- Degradation Problem–: As networks get deeper, the training accuracy gets saturated which indicates that all systems are not similarly easy to optimize. The figure below shows an example:
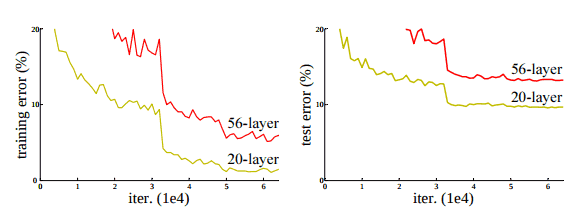
Errors on the CIFAR-10 dataset with 20 layers and 56 layer networks. Deeper network has higher training and test errors highlighting the degradation problem.
The Network in the Network approach
So, we had to get creative! After a lot of architecture engineering for convolutional neural networks was done by many research groups, we indeed found many such networks as Inception, Reset, SENet etc. These networks were not only deep but they also had repeated specific modules made up of a combination of convolutional filter banks, non-linearities and a careful selection of connections. Let’s look at one such module (ResNet module) in details:
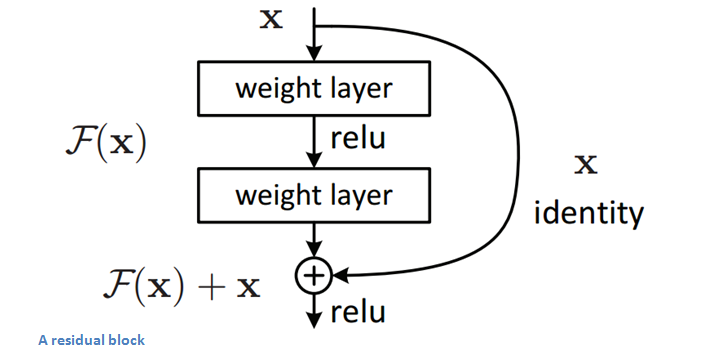
Resnet module proposed by Microsoft
Imagine a network called A which produces x amount of training error. Construct a network B by adding few layers on top of A and put parameter values in those layers in such a way that they do nothing to the outputs from A. Let’s call the additional layer as C. This would mean the same x amount of training error for the new network. So while training network B, the training error should not be above the training error of A. And since it DOES happen, the only reason is that learning the identity mapping(doing nothing to inputs and just copying as it is) with the added layers-C is not a trivial problem, which the solver does not achieve. To solve this, the module shown above creates a direct path between the input and output to the module implying an identity mapping and the added layer-C just need to learn the features on top of already available input. Since C is learning only the residual, the whole module is called residual module. To learn more of about these modules please read this earlier post. Here is how some of the earlier networks look like:




Neural Architecture Search(NAS) or AutoML:
Can we train neural networks to build a better neural network architecture? Yes, that’s exactly the idea behind Neural Architecture Search or popularly called AutoML.
Neural Architecture Search uses Reinforcement learning or evolutionary algorithms to learn architecture and weights which attain the highest accuracy for a given training dataset. In one of the approaches, we build a recurrent neural network which acts as a controller. The role of the controller is to design networks which will be trained on the given dataset and the results will be fed back to the controller which would help controller in iteratively design better networks. Initially, the controller selects a random child network. The child network is trained until it converges and the accuracy is calculated on a separate dataset. This accuracy number is fed to update the controller so that it generates better architectures as training progresses. In the beginning, the network selects simple and random child architectures but then over time it gets smarter and builds networks which are pretty good. Obviously, this is a computationally very expensive process, in one of the early experiments, 12800 architectures were trained to get the optimized architecture. Mostly this training is done in distributed mode, at any time 1000s of GPUs training a network.

Normally this process is very complicated and there are a lot many variables involved in deciding how one improves the network. In one of the attempts, a new neural network called NasNet(has many variants) was discovered which achieves the state-of-the-art accuracy on ImageNet dataset(96.2% top-5 accuracy, same as that of SENET-v1, the hand-crafted state-of-the-art at that time). However, Nasnet achieves this accuracy with less compute than SENET. Similarly, another recent attempt discovered AmoebaNet which matches the top-1 accuracy of the new state-of-the-art SENET-v2 i.e. 83.1%. This is very exciting because so far the search for a better generalizable network has been quite tedious and time-consuming. if we are to build on this framework of neural architecture search then the search for the ultimate Network would accelerate. Here is a table comparing the accuracy of various architectures on Imagenet:

Performance of various Neural Network architectures on Imagenet dataset
This means we can use Neural Architecture search to discover better architectures and everyone can use them. In my opinion, Neural Architecture search is an exciting academic approach which won’t be very popular in the industry considering the cost, the time required and limited benefits of custom architecture for a problem(In a recent paper, a team at Google discovered that for transfer learning, the better architectures on Imagenet do better on various datasets). However, the industry will benefit from the better and more efficient architectures discovered using it.


