Machine Learning Reality Check
In the Machine Learning World or broadly in the AI Universe, the colonists such as Data Scientists, Machine Learning Engineers, Deep Learning Specialist are coached towards a belief i.e. “More Training Data Means Highly Accurate Production Model“.

Which to some extent is unavoidably true but predominately it’s also a fact, that in the real world all training data samples or data points do not consist of the same level of information about various object instances across the dataset.
In short, More Data ≠ More Information
Modern Day Annotation Calamity
Currently, there is no denying that the eruption of high volumes of data from various available resources is driving businesses around the Computer Vision Industry.
However, the huge volume of data is toothless without the correct labels on it, and that where the invisible AI workforce (the team of labelers) joins hands with Machine learning Algorithms to sow the seeds of a process to build training data quickly.
But labeling activities in contrasting scenarios are generally hit by roadblocks such as :
1. Annotation task becomes too much Expensive
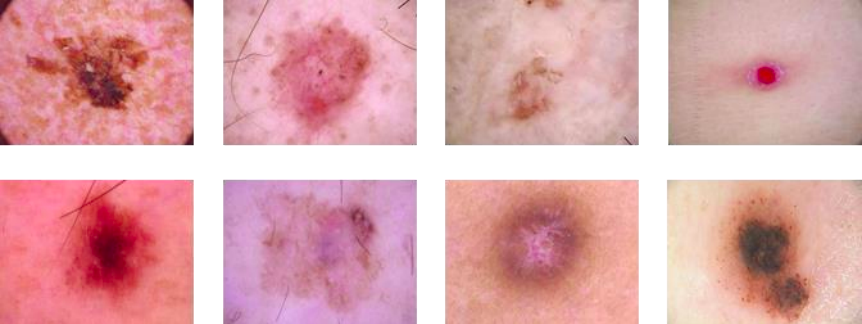
For Eg: Deep Neural Networks need annotations on training data to build models to efficiently and accurately diagnose diseases such as skin cancer and pneumonia at the very early stages.
But it’s always expensive to hire dermatologists to annotate thousands of skin cancer images
Or to employ radiologists (whose according to Glassdoor, have an average base salary of $290.000 a year and roughly $200 an hour) to perform segmentation annotations on CT scans data.
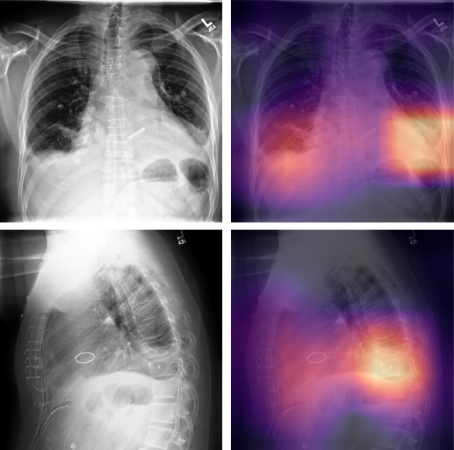
Therefore proper labeling of images oftentimes goes over the budget-making the annotation process too much expensive.
2. Annotation Tasks becomes too time-consuming and labor-intensive
For Eg: This kind of situation is generally observed in use cases such as shelf monitoring, planogram compliance, and retail audit. Where the labeling teams are asked to annotate 1000 to 10000 SKUs arranged on the supermarket shelf.

Facing such huge volumes of data and varieties of near similar SKU labels invariably end up demanding long manhours and strong precision by the teams of annotators.
3. Object Instances in Annotation tasks are hard to label
This level of label difficulties generally observed in use cases in which sensors other than the camera are also put in place to collect and create the training data.
For Eg: One such use case that comes to my mind is “landmine localization“.
In order to solve this problem, the ML engineers use 3 D B-scans volumetric data produce by ground-penetrating radar (GPR), which is put into action to reflect traces of landmine in the vicinity.
However, these objects must be labeled correctly with perfection because it’s almost the matter of life and death for the citizen of the countries where landmines are still buried in some places.

Well, after engaging yourself over the issues in data labeling, it’s time to look over to an approach that might have answers to the current annotation crisis.
Active Learning: A Strategy to tackle Labeling Bottlenecks
What is Active Learning?
Active Learning is a technique used by AI Engineers to tackle supervised learning systems in which the object/objects of interest label instances are hard, labor-intensive, or too expensive to acquire.
The key concept behind active learning states that “if the learning algorithm is allowed to choose the data (out of hundreds or thousands of annotated instances) from which it learns then it may perform well with less training
(i.e. ml model training)”. Thus ultimately ends up saving compute power and ML model cost.
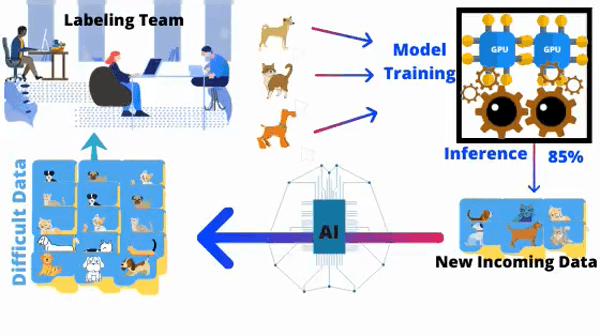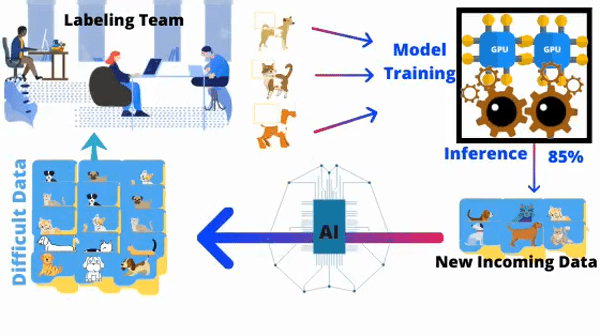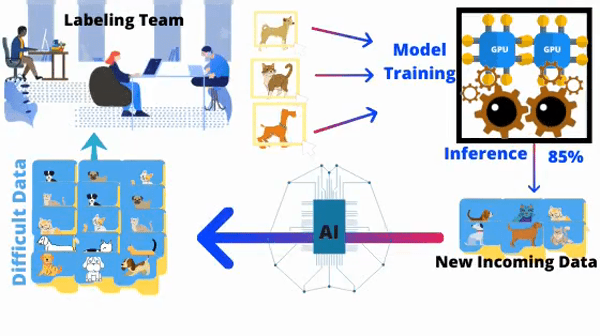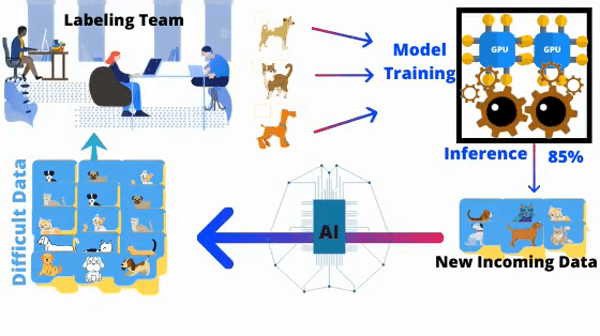
How it Functions
In order to overcome labeling challenges, the active learning systems ask queries in the form of unlabeled object instances, only which are hard to comprehend by the system.
Then a team of annotators labels those particular instances instead of entire training data and the AI model is trained again to develop a highly accurate model with few label instances.
Hence, active learning is a well-encouraged practice by ML specialists in trying to tackle Modern Machine Learning problems in which data is available in abundance but the label instances are insufficient or costlier to obtain.
Types of Active Learning
In the AI Literature, three types of learning strategies are predominantly talked about, which I will try to uncover narrowly in this section below:
Furthermore, these query-based approaches consistently assume that the queries raised by them in the form of unlabeled instances are always answered or labeled by the team of annotators.
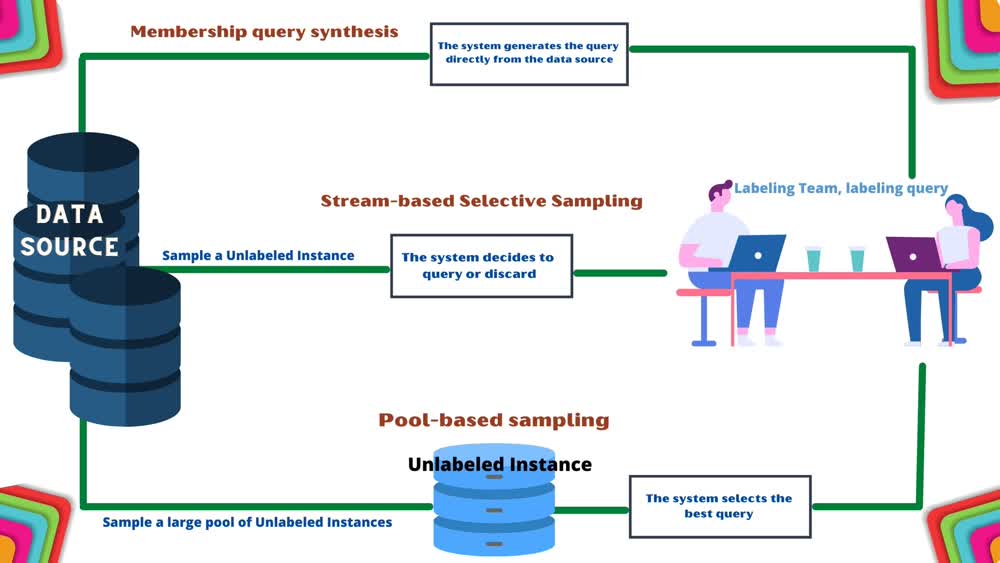
(A) Membership query synthesis
In this approach, the Active learning system generates queries on the unlabeled instances directly from the natural input distribution of the data and not from a derived sample instance of the data.
This particular approach is efficient for a finite no of industries where the labels over the unlabeled instances are not often created by oracle (human annotators) but by chemical experiments.
(B) Stream-based selective sampling
A key assumption followed in all these strategies is that obtaining the unlabeled instances is free or in-expensive in nature.
In this strategy, the Active learning system first samples some unlabeled instances and then decides individually whether or not to request its label from the oracle (human annotators) for it.
Extending the above notion, this type of investigation by the system is sometimes called sequential active learning.
As sequentially one by one the unlabeled data points are drawn from the data source and then going further the system decides on keeping or discarding their label request on the stream of unlabeled data points.
(C) Pool-based sampling
In this approach, the Active learning system extracts a huge pool of unlabeled data from the real-world data source.
After that, it evaluates and ranks that pool of unlabeled data points, and then selects the best query out of it for the human annotators to annotate.
Active Learning In Practice
In the sections above I talked about the labeling bottlenecks and why building training data is time-consuming and expensive.
Then I stirred this blog ship to a strategy called Active learning, its benefits, and its types available in AI literature.
Now, in this last part of the blog, I will briefly touch upon some of the challenges the Active learning approaches face when put into practice against the real-world data of the Modern-day Machine learning problem.
Some assumptions made by Active Learning research Mechanism:
- The entire set of unlabeled instances on which query is made is addressed or annotated by a single labeler.
- The labeler is always correct.
- The cost of labeling queries is free or uniformly expensive.
But you as a data scientist or as an annotation manager might agree with me too, that none of these assumptions stands true in real-world situations.
1. Batch mode active learning
In a research setup, an active learning system selects queries one at a time or serially. However, sometimes the ML model creation process is slow and expensive.
Furthermore, occasionally a distributed parallel labeling environment i.e. multiple annotators on different labeling workstations at the same time on a network are used to address the active learning system queries on unlabeled instances.
In both of the scenarios selecting queries, one by one may not be a good business decision.
Therefore in a realistic setup batch-mode active learning is deployed to allow the active learning system to query instances in a group, which is a better approach for ML models with slow training procedures.
Challenge
But this instance-level approach is bundled with a challenge i.e. how to properly assemble an optimized query set (Q) of unlabeled instances from the instance space.
Because from time to time these query sets fail to examine the overlap in information content among the best instances of the query sets.
2. Noisy Oracle (The human annotator)
In an experimental setup of an active learning system, it is assumed that the quality of labeled data produced by human experts is always high. But in reality, this is not true for a couple of reasons such as:
- some instances are inheritably difficult to annotate by humans and even by machines.
- humans can get fatigued or distracted over time, which directly introduces discrepancy in the quality of their drawn annotations over the object instances.
Challenge
Therefore in various engineering meetings, ML engineers always try to unearth this question that “how to use noisy oracles in the active learning setup whose quality varies over time“.
Nonetheless, the list of questions doesn’t end there because soon after that, they have to address one more inquiry i.e.
whether query for the (potentially noisy) label of a new unlabeled instance or for a repeated label to de-noise an existing training instance that seems a little bit different from others.


