Alexnet, which started the deep learning revolution, was loosely based on a network architecture(LENet) proposed by Yann Lecun in 1998. However, back then, we didn’t have the compute or the training data to train and produce the results like Alexnet. Alex used Nvidia GPUs for training, in fact he used two GPUs to train which split the network. Before that, GPUs were a toy for computer graphics and computer gamers. After Alexnet, GPUs were intensively used for training neural networks resulting in a multifold rise in revenue of Nvidia.
Rise of GPUs and NVidia:
In 2013, Google brain built a cluster of 2000 CPUs for deep learning costing 0.5 Million dollars. A similar setup can be created using just 3 GPUs with a cost of 33,000 dollars.

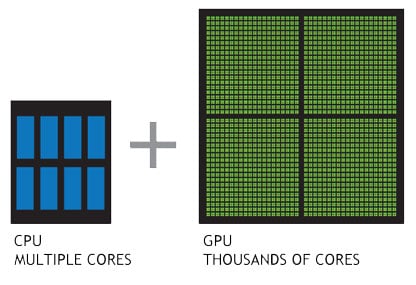
A CPU consists of a few cores which are optimized for sequential serial processing, on the other hand a GPU has massively parallel architecture consisting of thousands of smaller, more efficient cores designed for handling multiple tasks simultaneously.
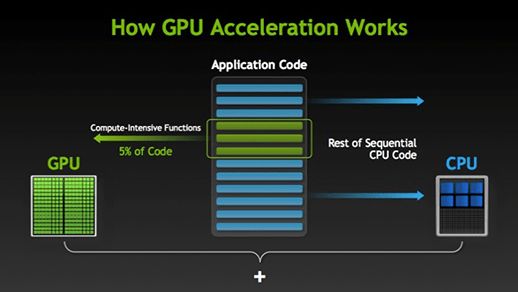
So, for deep learning, the CPU uses a GPU to run the most computationally expensive part of the algorithm while simple tasks are run on the CPU. So, In order to implement any decent deep learning algorithm, you need to have access to a CPU with a decent NVidia GPU.
CUDA (Compute Unified Device Architecture):
CUDA is NVIDIA’s parallel computing platform based on C. The point of CUDA is to allow developers to write code that can run on massively parallel architectures. In a way, CUDA is a software development toolkit that includes libraries, bindings and various debugging, profiling, compiling tools that allow programs running on CPUs to utilize the GPU.
cuDNN:
NVIDIA CUDA Deep Neural Network library (cuDNN) is a GPU-accelerated library for deep learning that runs alongside CUDA. cuDNN provides highly optimized implementations for standard neural network routines and operations. Using Cudnn provides huge acceleration to Deep Learning training and running deep learning training with CUDA and cuDNN is almost a requirement for any real-world deep learning application.
Performance Gain: Systems with CUDA accelerated GPUs can be 5-50x faster than a system with just a CPU.
Various libraries and frameworks:
There are many dedicated libraries which makes the task of implementing Artificial Neural Networks simple and quick. Here is a quick summary of few of the most popular ones:
- Theano:
Theano was a Python framework developed at the University of Montreal and run by Yoshua Bengio for research and development into state of the art deep learning algorithms. It used to be one of the most popular deep learning libraries. The official support of Theano ceased in 2017.
- Torch:
Torch (also called Torch7) is a Lua based deep learning framework developed by Clement Farabet, Ronan Collobert and Koray Kavukcuoglu for research and development into deep learning algorithms. The torch is used and has been further developed by the Facebook AI lab.
- Tensorflow: Tensorflow is an open-source Deep Learning by Google. It draws its popularity from its distributed training support, scalable production deployment options, and support for various devices like Android. It’s the same infrastructure that runs Google’s machine learning infrastructure in production.
- Caffe:
Caffe is a Python deep learning library developed by Yangqing Jia at the University of Berkeley for supervised computer vision problems. It used to be the most popular deep learning library in use. It only supports convolutional neural networks.
- MXNet: built and supported by Amazon, MxNet is also supported by the Apache foundation.
- CNTK: CNTK framework is maintained and supported by Microsoft.
- Caffe2: Supported by Facebook, built on the original Caffe. It is designed with expression, speed, and modularity in mind.
- PyTorch: PyTorch is one of the most popular deep learning framework which is gaining popularity due to its simplicity and ease of use.
- DeepLearning4j(DL4J): DeepLearning4J is another deep Learning framework developed in Java by Adam Gibson.
“DL4J is a JVM-based, industry-focused, commercially supported, distributed deep-learning framework intended to solve problems involving massive amounts of data in a reasonable amount of time.”
As you can see, that almost every large technology company has its own framework. In fact, almost every year a new framework has risen to a new height, leading to a lot of pain and re-skilling required for deep learning practitioners.
The world of Deep Learning is very fragmented and evolving very fast. Look at this tweet by Karpathy:
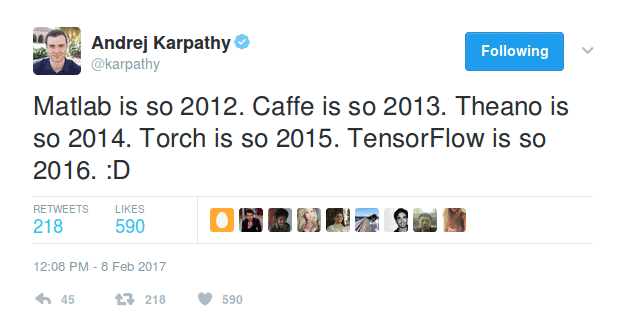
Imagine the pain all of us have been enduring, of learning a new framework every year. As of now, it appears that Tensorflow is here to stay.
Keras:
François Chollet, who works at Google developed Keras as a wrapper on top of Theano for quick prototyping. Later this was expanded for Tensorflow as back-end. Later, Tensorflow has decided to adopt it and provide it as part of contrib folder in the Tensorflow code.
Keras is being hailed as the future of building neural networks. Here are some of the reasons for its popularity:
- Light-weight and quick: Keras is designed to remove boilerplate code. Few lines of keras code will achieve so much more than native Tensorflow code. You can easily design both CNN and RNNs and can run them on either GPU or CPU.
- Emerging possible winner: Keras is an API which runs on top of a back-end. This back-end could be either Tensorflow or Theano. Microsoft is also working to provide CNTK as a back-end to Keras.
Currently, Keras is one of the fastest growing libraries for deep learning. The power of being able to run the same code with different back-end is a great reason for choosing Keras. Imagine, you read a paper which seems to be doing something so interesting that you want to try with your own dataset. Let’s say you work with Tensorflow and don’t know much about Theano, then you will have to implement the paper in Tensorflow, which obviously will take longer. Now, If the code is written in Keras all you have to do is change the back-end to Tensorflow. This will turbocharge collaborations for the whole community.
Pytorch got very popular for its dynamic computational graph and efficient memory usage.While, In Tensorflow, the graph is static and you need to define the graph before running your model. Although, Tensorflow also introduced Eager execution to add the dynamic graph capability. Dynamic graph is very suitable for certain use-cases like working with text.

MxNet is more of a deep learning framework for R. Although, it supports multiple layers and keras has got mxnet as a backend.
To solve this problem Open Neural Network Exchange (ONNX) was announced in the end on 2017 which aims to solve the compatibility issues among frameworks. So, you can train a network in PyTorch and deploy it in Caffe2. It currently supports MXNet, Caffe2, Pytorch, CNTK(Read Amazon, Microsoft, and Facebook). So, that could be a good thing for the overall community. However, it’s still too early to know. I would love if Tensorflow joins the alliance. That will be a force to reckon with.
One of the most awesome and useful things in Tensorflow is Tensorboard visualization. In general, during the training, one has to have multiple runs to tune the hyperparameters or identify any potential data issues. Using Tensorboard makes it very easy to visualize and spot problems.
Tensorflow Serving is another reason why Tensorflow is an absolute darling of the industry. This specialized grpc server is the same infrastructure that Google uses to deploy its models in production so it’s robust and tested for scale. In Tensorflow Serving, the models can be hot-swapped without bringing the service down which can be a crucial reason for many businesses.
Pytorch is easy to learn and easy to code. For the lovers of oop programming, torch.nn.Module allows for creating reusable code which is very developer-friendly. Pytorch is great for rapid prototyping and small scale or academic projects.
TensorFlow code gets converted into a graph by Python which is then run by the TensorFlow execution engine.
In Tensorflow, the entire graph(with parameters) can be saved as a protocol buffer which can then be deployed to non-pythonic infrastructure like Java.
One downside with Tensorflow device management is that it hogs all the memory on all the available GPUs by default even if only one of them is being used.
Support for Theano library was discontinued in 2017. Theano and many other libraries like Torch are getting sidelined with the new frameworks. The most suitable framework that is supposed to stand the test of time is Tensorflow with the heavy backing of Google. I don’t feel the same confidence with Caffe2 because Facebook is not known for a community-friendly approach to open-source software. Another thing, that is definitely going to survive in Keras. So, in this course, we shall learn these two libraries as they are an optimal choice for a long career in AI.
Google’s TPUs:
Tensor Processing Units (TPUs) are Google’s own custom chips for running machine learning workloads written for its TensorFlow framework. Google has been using TPUs on their data center for more than a year now, Currently, TPUs are not available to be bought separately, but one can access them using Google’s cloud platform. Compared to GPUs, TPUs are designed for a high volume of low precision computation with lower power consumption.
Key People in Industry and Academicians:

There are certain people that you must know and follow:
- Geoffrey Hinton:
Considered the GodFather of AI, Geoffrey Hinton divides his time between Google and the University of Toronto. He is known for many key original contributions such as backpropagation and Boltzmann machines.
- Yann Lecun:
Currently at Facebook, Yann Lecun is known for his contributions to convolutional neural networks which are one of the most fundamental concepts in Deep Learning.
- Yoshua Bengio:
Bengio is known for his fundamental work in autoencoders, neural machine translation, and generative adversarial networks.
- Andrew NG:
Founder of Coursera and former head of AI research at Baidu, Andrew NG is one of the key proponents of AI.
Edge Computing:
Since deep learning-based algorithms are very slow on CPUs, it becomes a problem to run them on a device in the wild. Imagine trying to do facial recognition on the data captured by a camera, it seems like a waste of time and resources to send the whole video to a cloud based server running 24×7. Putting a device at the point of action which processes the data locally is called edge computing. There are only a handful of devices like Nvidia Jetson tx1 and tx2 which are considered to be good candidates for edge computing.
Artificial Super Intelligence?:
Depending on it’s capability, AI can be classified into two types:
Artificial Narrow Intelligence (ANI): In other words Weak AI, Artificial Narrow Intelligence is AI that specializes in one task. AlphaGo, the AI program that beat the world Go champion in 2017, is only good at Go. Ask it to identify cats from dogs, and it would fail. AI systems that are being built today are mostly Weak AI. There have been attempts to train them at multiple tasks but the results are not that encouraging.
Artificial General Intelligence (AGI): Human-Level AI, Artificial General Intelligence refers to a system that is as smart as a human in performing different tasks—a machine that can perform any intellectual task that a human being can. We see this kind of AI in our movies and books. We are yet to create any kind of general AI, in fact, we are quite far from creating any.
Artificial Superintelligence (ASI): Artificial Super Intelligence refers to an intellect that is much better than the best human brains in every task including reasoning, science, creativity and social skills. Artificial Superintelligence could be just a little smarter than a human or a million times smarter. Hinton has stated that ASI seems more than 50 years away, but he also warns that “there is not a good track record of less intelligent things controlling things of greater intelligence”.
Will we ever be able to build a superintelligence? If yes, will that mean end of the human race? All these questions make AI a topic of discussion at parties and the topic of various movies and books.
Reference:
https://developer.nvidia.com/cudnn
One model to learn then all https://arxiv.org/abs/1706.05137


